Building Effective AI Agents
Anthropic 工程实践:别一上来就套 Agent 框架。先搞懂增强型 LLM,再按任务选工作流或自主 Agent,并设好生产护栏。
结论
Anthropic 和几十个客户团队做过 Agent 之后,发现一个反直觉的结论:最成功的 Agent 往往不是最复杂的那个。很多人一上来就选型 LangChain、CrewAI 这类框架,但真正管用的情况是——先用模型 API 加上检索、工具、记忆,搭出最小可用方案;确认有价值后,再按任务特点加工作流;只有步骤根本没法提前规划时,才上自主 Agent 循环。
要点
-
一切从「增强型 LLM」开始。 就是在普通大模型外面加三样东西:检索(查文档/数据库)、工具(调 API、跑代码)、记忆(记住上下文)。下图是 Anthropic 原文的底座示意。别跳过这一步直接上「全自动 Agent」。
-
多数任务用工作流就够,不必自主 Agent。 工作流的意思是:步骤大致能提前想清楚,用固定模式编排 LLM 调用。常见五种——
- 提示链:一步一步来,上一步输出给下一步(比如先提取字段,再生成报告);
- 路由:先分类,再分流(比如客服先判断是退款还是技术问题);
- 并行化:多个子任务同时跑,再汇总;
- 编排者-执行者:中央模型动态拆任务、派给子模型;
- 评估者-优化者:一个写、一个评、循环改到达标。 每多一层 LLM 调用,就多一分延迟、成本和出错概率——能简单就别复杂。
-
什么时候才上自主 Agent? 当「要几步、先干哪步」事先说不清,必须边做边看环境反馈时。典型例子是编程 Agent:改代码前不知道要动哪些文件,得根据仓库状态动态决定。这时才用「模型决策 → 调工具 → 看结果 → 再决策」的循环。
-
上生产有三条硬规矩。 ① 每步从环境拿地面真相(工具返回的 JSON、代码执行输出),别只听模型说「我觉得搞定了」;② 写数据库、发邮件、部署这类操作前加人工检查点;③ 设
max_iterations上限,防止无限循环烧钱。
怎么做
如果你刚开始做 Agent,可以按这个路径走:
-
第一周:单轮增强型 LLM + 一两个工具。 比如「查内部文档 + 回答用户问题」。先验证有没有人用、有没有省时间,别急着搭多 Agent 编排。
-
第二步:按任务选模式。 步骤固定 → 提示链或路由;要拆成很多独立子任务 → 并行或编排者-执行者;要反复打磨质量 → 评估者-优化者。工具函数的说明要写清楚(参数什么意思、失败返回什么),模型才不容易乱调。
-
第三步:加生产护栏。 定义什么叫「完成」(可观测的输出,不是一句空话);敏感操作必须有人点确认;日志记全每步输入输出,方便排查。
-
上线前自问: 加这一层编排,质量真的提升了吗?还是只是更炫、更慢、更贵?用真实任务 A/B 一下再决定。
关键图表
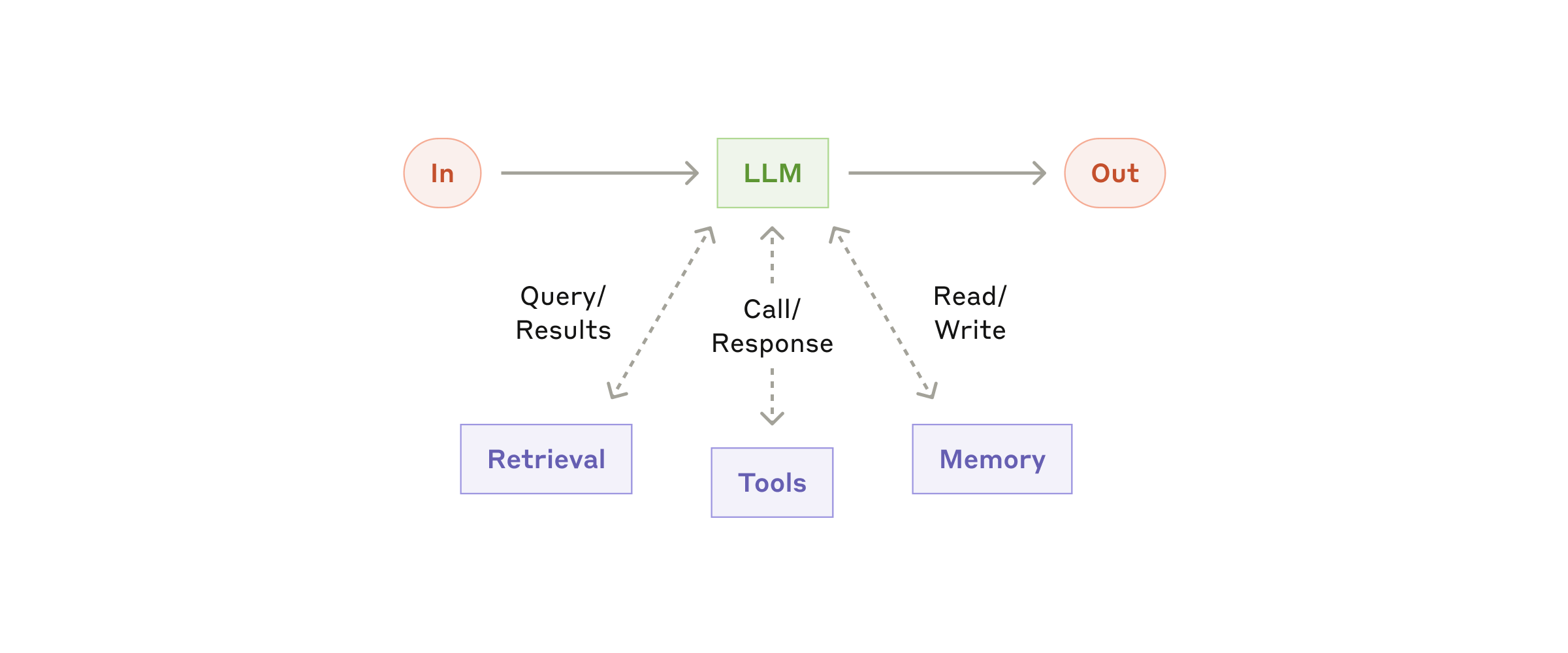 增强型 LLM(Anthropic 原文)——后续所有工作流模式都建在这三层能力之上
增强型 LLM(Anthropic 原文)——后续所有工作流模式都建在这三层能力之上